Polimorfismos de Nucleotídeo Único e Gene BRCA 2
O Futuro é inactivarmos a doença no gene através do desenvolvimento de um micro nanorobot avançado
Sandra Cruz
Genómica é o estudo do material genético dos organismos. Inclui o estudo de métodos para conhecer a localização e a sequência dos genes. O splicing alternativo é um método para expressão gênica que resulta na formação de múltiplas proteínas a partir de um único gene. A sequência de DNA pode incluir uma sequência codificadora e não codificadora. O gene BRCA2 é um gene importante que codifica uma proteína que ajuda a manter a informação genética pelo reparo do DNA.
Índice
Introdução aos Genomas
Número de Genes e Complexidade
Localização Gene
Splicing Alternativo
Tipos de sequências de DNA
Elementos transponíveis
Polimorfismo de nucleotídeo único
Referências
Image: “From DNA to Life” by Dodo. License: Public Domain
O conjunto completo do material genético de um organismo é chamado de genoma. Um genoma consiste em DNA (ou RNA para RNA vírus) que inclui os genes (região codificante), DNA não codificante e DNA (ou RNA) das mitocôndrias também.
O termo genoma foi cunhado em 1920 por Hans Winkler. Este termo é uma combinação de genes e cromossomas.
Dentro do núcleo de uma célula humana são 23 pares de cromossomas contendo fitas de DNA. Cada DNA de braço consiste de quatro bases nucleotídicas (adenina (A), timina (T), guanina (G) e citosina (C)), que estão dispostas em uma sequência específica que determina os genes.
Um genoma contém todas as informações necessárias que um organismo necessita para produzir, manter e reproduzir. Cada genoma do corpo humano contém mais de 3 milhões de pares de bases de DNA, e tudo isso se encaixa dentro do núcleo microscópico de cada célula.
Número de Genes e Complexidade
O número de genes não determina a complexidade de um organismo. Existem 50.000 genes no milho, 45.000 no arroz, até 25.000 genes em humanos e 13.600 genes em uma mosca doméstica.
Localização Gene
Os genes podem ser localizados em uma fita de DNA, procurando por códon de início, códon de parada e quadro de leitura aberta (ORF), que é a região entre o códon inicial e final.
Inspecção de sequência
Os genes não são uma série de sequências aleatórias de nucleotídeos, mas sim uma sequência e característica específicas; Assim, a inspecção de sequência pode ser feita para localizar genes no DNA. A sequência particular e os recursos ajudam a determinar se uma determinada sequência é um gene ou não.
A inspecção de sequências é geralmente o primeiro método para analisar a sequência genética. Não é um método infalível de análise, mas, sem dúvida, uma ferramenta útil para localizar genes.
Quadros de Leitura Aberta ORF
A ORF começa com um códon de início, que tem a sequência de base de nucleotídeos como ATG e termina no códon final que consiste de um TAG, TAA ou TGA. Cada cadeia de DNA tem três quadros de leitura em uma direção e três na outra linha na direção oposta; Assim, ambos os fios terão seis quadros de leitura.
A informação armazenada nos genes no DNA é transcrita em mRNA e depois traduzida em proteínas. No entanto, antes da formação de proteínas, os intrões (partes não codificadoras de uma sequência genética) devem ser removidos e os exões (partes codificantes das proteínas) do mRNA devem ser unidos para que se traduza em proteínas.
O splicing alternativo é um método regulado durante a expressão gênica que resulta na formação de múltiplas proteínas a partir de um único gene. Isto envolve a inclusão ou exclusão de um exão particular do ARNm final e resulta na formação de uma variedade de proteínas com diferentes sequências de aminoácidos e diferentes funções. Assim, mesmo que o número de genes em um organismo seja menor, o espaço para complexidade pode ser aumentado em grande parte devido ao processamento alternativo de mRNA.
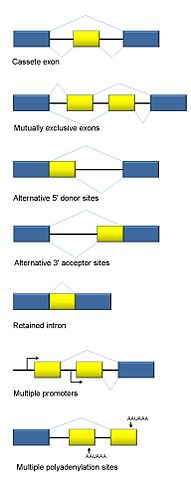
Modos de emenda alternativa
Cinco modos de splicing alternativo são:
1.Exon Skipping (Cassette Exon)
2.Exons mutuamente exclusivos
3.Site doador alternativo
4.Local do aceitador alternativo
5.Retenção intron
O método de determinar a ordem exacta das bases de nucleotídeos em um DNA é chamado de sequenciamento de DNA.
Os tipos de sequências de DNA incluem
1.Codificação de sequências de DNA
2.Genes de cópia única
3.Duplicações segmentares
4.Famílias multigênicas
5.Aglomerados em tandem
Sequências de DNA não codificantes
Intron
DNA estrutural
Repetição de sequência simples
Duplicações segmentares
Elementos transponíveis
Pseudogenes
Micro RNAs
ARN longo não codificante
Codificação de sequências de DNA
Estas são as regiões do DNA que codificam proteínas.
Genes de cópia única
Eles são transcritos para formar RNA que é traduzido para formar proteínas.
Duplicações segmentares
São sequências longas de DNA e são quase idênticas (90% - 100%) em sequência. Eles estão presentes em vários locais devido à duplicação de eventos. Pode ser em tandem ou intercalado e intercromossômico ou intracromossômico.
Famílias multigênicas
Inclui um grupo de genes do mesmo organismo que forma proteínas com uma ordem semelhante, seja ao longo de toda a extensão do gene, seja através de um domínio parcial. A duplicação de DNA pode formar pares de genes, e uma família multigênica se formará se ambas as cópias nas gerações subsequentes existirem. Genes que codificam para hemoglobina, actinas, interferon, histonas, etc. são exemplos de famílias multigênicas.
Genes em tandem e genes de cluster
Os genes em tandem estão presentes no segmento de DNA que são repetidos várias vezes da cabeça à cauda. Os genes de cluster são conectados por DNA não conservado, mas irregularmente espaçados e invertidos imprevisivelmente.
Sequências de DNA não codificantes
Estas são as regiões do DNA que não codificam proteínas.
Intrões
É uma sequência nucleotídica de um gene em DNA ou RNA que não está incluído e separado durante a formação final de mRNA e não codifica para a formação de proteínas.
Pseudogenes
Eles são genes que não codificam para proteínas devido a mutações como frameshift ou códons de parada prematuros.
Elementos transponíveis
Também chamados de transposons ou genes saltadores, eles são a sequência de genes no DNA que se movem de um lugar para outro dentro de um genoma. Eles podem ser duplicados ou extirpados e inseridos em outro lugar. Incluem Linters de Elementos Intermediários Longos (21%), Sines de Elementos Intercalados Curtos (13%), Terminal Longo repete LTRs (8%) e Transposons Morto (3%).
Esses elementos se movem de um local para outro; eles podem ser:
1. Duplicado
2. Extirpado - Se extirpados, esses elementos são inseridos em outro lugar.
Tipos de elementos transponíveis
1. transposons mortos: Este 3% do genoma não tem maquinaria para se mover.
2. terminal longo repete LTRs: 8% do genoma humano é LTRs. Eles contêm transcriptase reversa.
3. Elementos intercalados curtos (SINEs): 13% do genoma humano consiste em SINEs. Estes são aninhados em elementos longos intercalados.
4. Longos elementos intercalados (LINEs): Eles formam até 21% do genoma humano. LINHAS podem se transpor.
Os restantes 55% fazem o ADN não codificante e codificante no genoma humano.
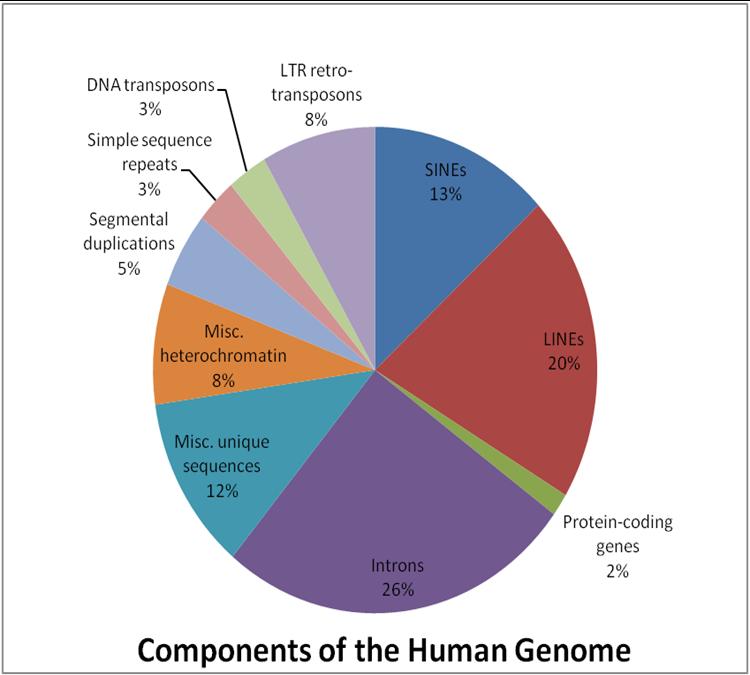
Image: “This figure illustrates the proportion of various genomic components within the human genome.” by Alglascock. License: CC BY-SA 3.0
O polimorfismo de nucleotídeo único (SNP) é o tipo mais comum de variação na sequência de DNA que ocorre quando um único nucleotídeo (A, T, G ou C) varia entre membros de uma espécie ou mesmo entre cromossomos pareados dentro de uma pessoa. Essas mudanças podem ser responsáveis pela diversidade entre as pessoas e alguns traços familiares comuns, como diabetes, hipertensão, cabelos crespos, resposta a drogas, etc.
Os SNPs são usados para identificar genótipos. Os SNPs conhecidos foram mapeados nas sequências do genoma.
Os SNPs são encontrados em um DNA humano. Eles ocorrem em todos os 300 nucleotídeos. Eles desempenham um papel importante como marcadores biológicos para localizar genes em condições de doença e afectando directamente a função do gene. De acordo com recentes trabalhos de pesquisa, os SNPs podem contribuir para julgar a resposta individual a certos medicamentos e certos factores ambientais, como toxinas e risco de desenvolver doenças. Pode tratar a herança de genes de doenças em famílias.
Gene BRCA2
Este gene instrui a formação de proteína supressora de tumor que ajuda a prevenir o crescimento e multiplicação incontroláveis das células. Esta proteína também está envolvida na reparação dos danos causados por factores como radiação ou algumas exposições ambientais; Assim, esta proteína (e, portanto, o gene) visa manter e preservar a informação genética.
Tag de Sequência Expressa (EST)
O EST é uma parte da sequência de cDNA na forma de uma subseqüência curta. Na determinação da sequência gênica e descoberta do gene, Expressed Sequence Tag é instrumental. Estes também são usados para a identificação de transcritos de genes.
Em genética, o EST ajuda a determinar quais partes do genoma são expressas.
Microarray
Um microarray contém genes catalogados de um genoma inteiro. Eles podem dizer quando um gene é expresso.



{kind=link}
{kind=link}
Comentários
Enviar um comentário